背景知识
分析性能调优和性能问题都需要相关的背景知识。如果刚好是在业务上接触比较多的同学,在碰到相应的问题就会到处尝试,最后才能定位问题。而这里的重启导致load问题其实不算是一个问题,是一个HotSpot在高TPS下必然会出现的现象。
HotSpot VM 是采用 解释执行 + JIT(just-in-time 即时) 编译器编译热点(这就是 HotSpot VM 名字的由来)代码的方式运行。
编译部分是 java 字节码编译成机器本地代码 native code 来运行,这里就和gcc的效果一样。而且基于运行时的采集数据去做优化,HotSpot VM 得 JIT 可以做得和gcc不相上下,换句话说就是在不同应用场景各有胜负。
在Client Compiler(简称C1,轻量级编译器,fast,效果大概和gcc -o1类似)下运行,运行次数达到1000就会触发编译。
在Server Compiler(简称C2,重量级编译器,smart,效果大概和gcc -o2类似)下运行,运行次数达到10000时触发编译。
在开启多层编译,即-XX:+TieredCompilation,代码首先运行在解释模式,达到C1阈值2000之后,触发C1编译,达到C2阈值15000后,触发C2编译。
编译工作由后台的 Compiler Thread 并发完成,这个过程自然就会抢占cpu资源。
后台的编译线程数 由flag -XX:CICompilerCount 来决定.可以使用 -XX:+PrintFlagsFinal 来观察jvm运行时的具体参数值是多少。非多层编译下 CICompilerCount 的默认值是2。
C:\Program Files\Java\jdk1.6.0_45\bin>java -XX:+PrintFlagsFinal -version| grep CI
intx CICompilerCount = 2 {product}
bool CICompilerCountPerCPU = false {product}
bool CITime = false {product}
bool ExplicitGCInvokesConcurrent = false {product}
bool ExplicitGCInvokesConcurrentAndUnloadsClasses = false {product}
java version "1.6.0_45"
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
Java HotSpot(TM) 64-Bit Server VM (build 20.45-b01, mixed mode)
另外一个涉及线程数目运算的标识符是CICompilerCountPerCPU,逻辑是当CICompilerCountPerCPU == true时,_compiler_count = max(log2(8)-1,1)。
void NonTieredCompPolicy::initialize() {
// Setup the compiler thread numbers
if (CICompilerCountPerCPU) {
// Example: if CICompilerCountPerCPU is true, then we get
// max(log2(8)-1,1) = 2 compiler threads on an 8-way machine.
// May help big-app startup time.
_compiler_count = MAX2(log2_intptr(os::active_processor_count())-1,1);
} else {
_compiler_count = CICompilerCount;
}
}
hotspot/src/share/vm/runtime/compilationPolicy.cpp
如果在重启之后,卡在解释模式的时间太久导致性能不理想或者出现雪崩现象,可以把-XX:CICompilerCount这个参数的值适量加大。这样load会在重启之后升高,但是会很快降下来,因为更多的线程已经编译完了。
另外一方面,jit这种典型的PGO(profile guide optimization)所带来的带来的问题,当下一次行为和之前的完全不同(uncommon trap),那么native code就会回滚(deoptimization)到 interpret,然后再次采集数据进行下一次优化。jvm启动初期会不断的经历 profile -optimization-uncommon trap-deoptimization-profile -optimization-uncommon trap-deoptimization….-optimization.最后达到一个稳定状态。
public void sendMail(User user){
if(user.isVip()){
sendMail();
}
}
public void deletlUser(User user){
deleteUser(user);
sendMail(user);
}
经过inline和编译会被展开成如下形式
public void sendMail(User user){
if(user.isVip()){
sendMail();
}
}
public void deletlUser(User user){
deleteUser(user);
if(user.isVip()){
sendMail();
}
}
再比如前一万次调用的user不是vip,那么就做一次激进优化
public void sendMail(User user){
if(user.isVip()){
sendMail();
}
}
public void deletlUser(User user){
deleteUser(user);//sendMail 行为完全被消除。
}
问题来了,突然来了一次user.isVip() == true 的调用,那么jvm会立马退回到解释执行,然后接着靠收集的数据来做依据做优化。
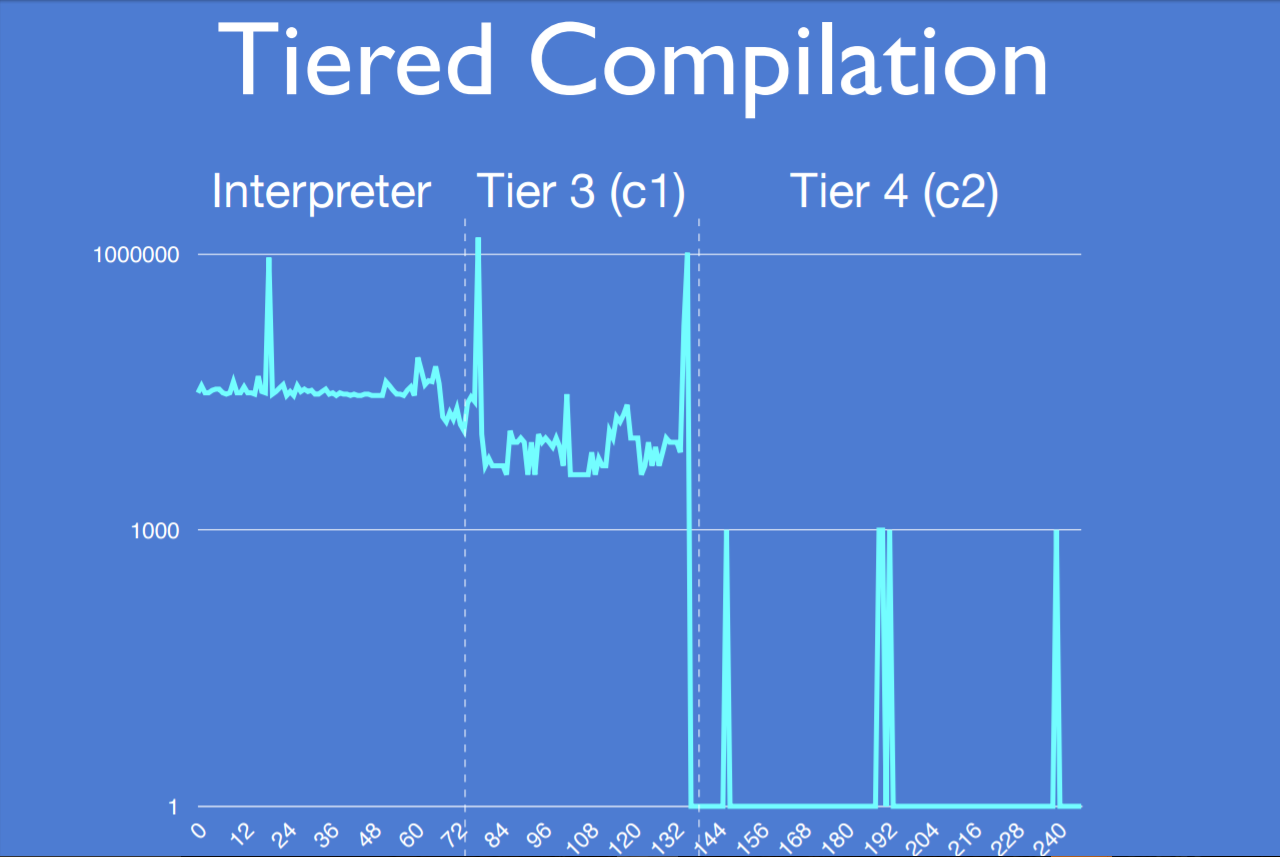
既然 JIT 每次都需要编译,那么能不能在业务数据变动不大的情况下使用前一次的编译结果来节省编译时间呢。答案是有的,这种编译器叫AOT(ahead-of-time)编译器,事先编译器。它可以将上一次的JIT结果序列化保存到本地,下一次再使用这些结果。目前主流的jvm中,IBM J9 VM和 Azul zing VM都有相应的功能,未来发布的jdk9也会有AOT编译器。IBM J9 VM就叫AOT编译器,J9的AOT会有一些性能问题,使用AOT编译器产生的编译结果性能不如JIT编译器的性能好;而Azul zing的AOT编译器就换了个马甲,改了名字叫 Ready now!,是Zing JVM的主要竞争力之一(更主要是C4 垃圾回收器,完全并发整理回收器,stw的时间在个位数ms级别)。 Ready now!的作者也做过一个jit的演讲,jvm-mechanics-github,相应的视频在youtube和Azul都能找到,这里是演讲的文件,看一下pdf应该可以了解不少。这里引用其中一幅图来说明一下jit的威力和解释执行到底有多慢。
JDK9带的AOT编译器是基于Graal编译器来做的。Graal也是OpenJDK项目的一个子项目,目标是取代现在的C1和C2,推特的jvm就直接使用了Graal而没有使用C1&C2。JEPS-295这个页面是对JDK9中的AOT编译器的介绍,具体的性能可以等JDK9发布以后看看。
那么现在知道了,解释执行和jit编译会倒是jvm启动阶段的效率低和load高,那么怎么来监控这个行为呢。
监控jit
几个办法:使用jvm参数来监控jit的编译;使用jmx/JFR来监控jvm的编译。还可以使用perf top之类的命令来查询占用cpu高的线程。
1.打印编译日志
使用 -XX:+PrintCompilation 编译的日志就会打印在console里面,如果需要更详细记录到文件的话,就加上 -XX:+LogCompilation -XX:LogFile=<path to file>,这两个flag会开启记录xml格式的更详细编译日志。
console的编译日志大概长这个样子
289 1 3 java.lang.String::hashCode (55 bytes)
290 2 3 java.lang.String::equals (81 bytes)
293 3 3 java.lang.String::indexOf (70 bytes)
294 6 n 0 java.lang.System::arraycopy (native) (static)
295 4 3 java.lang.String::<init> (82 bytes)
297 7 3 java.lang.Object::<init> (1 bytes)
304 13 4 java.lang.String::charAt (29 bytes)
306 12 4 java.lang.String::length (6 bytes)
307 8 4 java.util.TreeMap::parentOf (13 bytes)
308 10 3 java.lang.CharacterData::of (120 bytes)
310 11 3 java.lang.CharacterDataLatin1::getProperties (11 bytes)
311 9 3 java.lang.Math::min (11 bytes)
316 14 3 java.lang.Character::toUpperCase (6 bytes)
317 5 3 java.util.Arrays::copyOfRange (63 bytes)
320 15 3 java.lang.Character::toLowerCase (9 bytes)
321 16 3 java.lang.CharacterDataLatin1::toLowerCase (39 bytes)
322 17 ! 3 java.io.BufferedReader::readLine (304 bytes)
327 18 3 java.lang.AbstractStringBuilder::ensureCapacityInternal (16 bytes)
328 19 3 java.lang.String::getChars (62 bytes)
335 20 3 java.lang.AbstractStringBuilder::append (29 bytes)
336 21 3 java.lang.StringBuilder::append (8 bytes)
339 22 3 java.io.WinNTFileSystem::isSlash (18 bytes)
340 24 s 3 java.lang.StringBuffer::append (13 bytes)
342 25 3 java.lang.StringBuilder::append (8 bytes)
342 23 3 java.lang.String::indexOf (7 bytes)
344 26 3 java.lang.System::getSecurityManager (4 bytes)
345 27 1 java.io.File::getPath (5 bytes)
352 28 3 java.lang.AbstractStringBuilder::<init> (12 bytes)
354 29 3 java.lang.AbstractStringBuilder::append (50 bytes)
356 30 3 java.lang.String::startsWith (72 bytes)
356 32 1 java.lang.Object::<init> (1 bytes)
357 7 3 java.lang.Object::<init> (1 bytes) made not entrant
359 31 3 java.lang.String::startsWith (7 bytes)
363 33 1 java.util.ArrayList::size (5 bytes)
364 34 3 java.util.HashMap::hash (20 bytes)
369 35 3 java.lang.String::substring (79 bytes)
371 37 3 java.util.HashMap::putVal (300 bytes)
376 38 3 sun.util.locale.LocaleUtils::isUpper (18 bytes)
377 36 3 java.util.HashMap::put (13 bytes)
388 39 3 java.util.jar.Attributes$Name::isValid (32 bytes)
389 40 3 java.util.jar.Attributes$Name::isAlpha (30 bytes)
391 41 4 sun.misc.ASCIICaseInsensitiveComparator::toLower (16 bytes)
391 42 4 sun.misc.ASCIICaseInsensitiveComparator::isUpper (18 bytes)
第一行是jvm的启动之后的事件 第二行是compilation id 编译任务id 第三行是一些标识符
b Blocking compiler (always set for client)
* Generating a native wrapper
% On stack replacement
! Method has exception handlers
s Synchronized method
第四行是多层编译的日志,在 Tiered Compilation 为false 时,没有这一行。该列表明是这次编译是第几层的编译(多层编译有0,1,2,3,4几层)。
第五列就是具体编译的方法以及方法大小了。第五列后面可能会有 made not entrant 以及 made zombie 这样的标识。
另外一个用来事后分析jit行为的工具是jitwatch。
2.使用JFR来观察jit
JFR 是嵌入到jmc (Java Mission Control)的一个jvm性能采样工具,从 JRockit VM 中移植到 HotSpot VM。 在安装jdk7以后版本都应该有这个jmc工具。使用JFR需要解锁商业特性,换句话就是再生产环境需要给ora买授权,但是你测试环境用是没事的,所以测试可以尽情的用。alijvm实现了自己的JFR,不得不说ali团队的强悍。
JFR用默认配置就可以采集到编译信息了。如下图所示。