近来看很多人都在周期性讨论为什么 HotSpot VM 有两个S区,很多人会拿出复制算法的特性来解释,但是基本的复制算法的空间结构是 semi-space ,一个form,一个to。和HotSpot VM的分区完全是风马牛不相及。而且复制算法是一个基础算法,很少有直接在堆分部上使用复制的VM。
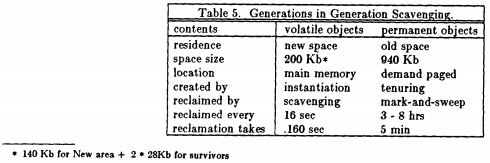
HotSpot VM 的堆分布来源于 Ungar 的在1984年发布的论文《Generation Scavenging : A Non-Disruptive High Performance Storage Reclamation Algorithm》.
原始的复制算法是在在两个半空间来复制,这样导致的一个问题就是空间浪费太严重。整个新生代的一半内存被占用却无法使用。另外一点是新生代的to区不许需要那么大,因为大多数都对象在新生代的gc就已经被回收了。所以semi-space的问题就是太浪费空间。所以分成了eden + s0 + s1 的组合。HotSpot VM 默认的配置是8:1 : 1
占用内存=oldgen used + newgen used + s*2;
可用内存=Heap size - oldgen used - newgen used - s ;
再说一下某些禁用了s区的jvm配置,实际就导致了原本会在存活阈值之后提升到老年代的对象在经过一次gc以后就直接晋升到了老年代,导致大量短命对象会提前晋升到老年代。晋升到老年代的对象越多,就导致老年代的碎片化越快。
平时大家都知道老年代的gc比较慢(更多的认知是fullgc慢),那么晋升到老年代会带来什么影响呢。
首先是在晋升到老年代时,就会碰到第一个问题。对象在老年代的分配。
老年代使用CMS算法时,是采用mark-sweep为主,mark-compact备份的措施。
在经过标记-清除算法的清除阶段之后,堆就变成了一片一片的零碎空间。有一个 free_list 链表来记录空闲空间,对象分配时,就需要遍历 free_list 通过 first_fit 来找到第一个适配的空间来做对象,这个分配过程是针对整个堆的,还需要做同步处理。而新生代的copying,每次gc之后,目标区域都是一块完整连续的空间,可以采用 bump_pointer 指针碰撞的方式来做分配,直接使用了内存以后,将指针往后移对象大小就行了。新生代的一个优化是线程本地分配缓冲池,每个线程每次去获取一块空间,每个线程管理自己的 bump_pointer ,线程本地的分配在这个TLAB里面做。从而避免全局竞争锁。
说完了分配,就该说清楚了。
上一个图,来自 Ungar 原始论文中的gc速度表。 可见老年代的回收速度确实慢的令人发指。